
Eredis - An updated Emacs Redis API
In July 2011 I released an emacs lisp client for the Redis in-memory data structure store. You can install either from the Melpa package or just clone from Github. The current version at time of writing is 0.9.6 and you will need that or later for some of the examples below to work.
In my spare time over the last few weeks I have been steadily improving eredis by fixing bugs, adding support for multiple connections, modernizing the use of emacs lisp and adding some features like iterating and mapping over all the keys in the Redis DB.
In this article I will re-introduce eredis and describe some of these changes, as well as going into some details about how it works under the hood.
Possible uses of eredis
- Debugging your applications. A convenient way to view the data in Redis that uses the full power of Emacs buffers and emacs lisp
- Monitoring. Using the hooks to org mode you can load a list of key/values into an org table. With lively.el you can update it periodically. Now emacs is a realtime monitoring tool!
- Data processing. Using iteration and reduction functions in eredis you can scan over all the keys in Redis and perform calculations on your data.
- Scripting and testing. Use the full power of emacs lisp to create test data or simulate users for test cases.
Installation and preparation
Installation instructions can be found in the Github README.md file. Next you will need access to a Redis database. You can run a local test Redis instance using Docker. There are two scripts in the github repo to let you run two instances; one on port 6380 and the other on the default port 6379. This is because you can connect to multiple Redis servers using eredis. Also note we’re using Redis 5.0 so we can try out the newer commands.
docker run -d -p 6379:6379 --name redis5_80 redis:5.0.0-alpine
docker run -d -p 6380:6379 --name redis5_81 redis:5.0.0-alpineConnections and basic commands
Each connection to Redis creates an emacs process. To write a network client you use a network process. The following commands open network processes to your Redis instances.
(require 'eredis)
(setq rp (eredis-connect "localhost" 6379))
(setq rp2 (eredis-connect "localhost" 6380))Note that the return value is a process. We can then pass that in as the final parameter to most eredis calls, so it knows where to route the command. If you omit the process it will use the last opened process by default. This ensures backwards compatibility with older eredis versions.
Let’s try a couple of basic commands. Imagine our application stores users and the time they logged in as string key that looks likeuser:ID and a value which is the timestamp. We’ll set two users that have logged in at the same time, one in each instance:
(eredis-set "user:61" "1542084912" rp)
(eredis-set "user:62" "1542084912" rp2)Now you can check the data is stored correctly:
(eredis-get "user:61" rp)
(eredis-get "user:62" rp2)When we issue a Redis command it is sent to over the network using the function process-send-string and the response from Redis will be sent to an emacs buffer associated with the process. After the two commands above you’ll see the buffers look like this:
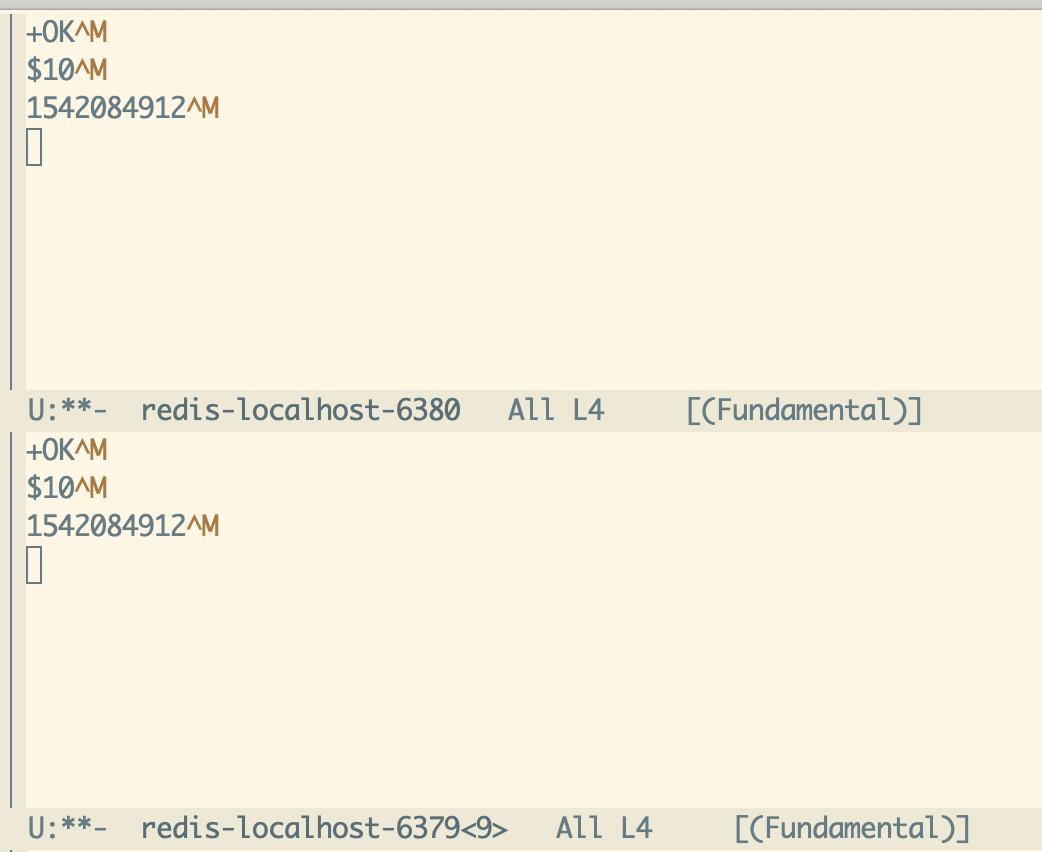
Notice that the buffers contain the pre-parsed RESP protocol. Using buffers in this way lets you see the history of output from Redis, which helps with debugging and also maybe useful depending on how you use eredis. After the command is sent to Redis eredis will call accept-process-output which is a signal to Emacs to check for any data received over the network connection and put it in the buffer. This function can return immediately if there is no data, so you have to keep calling it until you’ve got a fully formed response.
If the buffers start to get big or you want to clear them, you can do so with eredis-clear-buffer passing the process as the parameter. You can also disconnect from the process once you are done either by using the command eredis-disconnect or by killing the process in the window you get if you run the list-processes command.
Lolwut
Salvatore Sanfilippo recently wrote in Redis news LOLWUT: a piece of art inside a DB command about how from version 5 onwards LOLWUT will do something fun. Currently that draws a piece of randomly generated art using the braille unicode characters. eredis supports that command. eredis-lolwut returns the lolwut art.
Note that it won’t look like this necessarily. In Emacs 26.1 running on macOS Mojave I had to download a few fonts before I found one that rendered correctly called Swell Braille.
A note on multibyte string handling
In early versions of eredis there was a bug reading multibyte character data. Redis, as you may know, only deals with bytes. Whatever encoding you’re using for strings on the client side, you send byte strings to Redis and it sends those same strings back. In eredis the buffer is set to multibyte mode, so if you receive multibyte characters they will display correctly there:
(eredis-set "hello-chinese" "你好吗") ;; "OK"
(eredis-get "hello-chinese") ;; "你好吗"So to the user of eredis everything works. But this is not automatic, take this example:
(length "你好吗") ;; 3
(length (string-as-unibyte "你好吗")) ;; 9Emacs returns the length of a multibyte string as the number of characters, not the number of bytes. But Redis returns this string as follows:
$9
你好吗In other words Redis sends a string of 9 bytes. You need to be careful when parsing RESP data to count actual bytes and not characters. In eredis I convert between multibyte and unibyte strings to make sure the parser works correctly, before passing the final multibyte string to the caller. org mode integration Note that you need version 0.9.6or later for this section as I had to fix some bugs and make some improvements for this flow to work correctly. Please note that the org functions don’t obey the process parameter, and they work on the last opened connection only. If you only have one connection open you should be fine. A fix for this will be in the next release. Data from Redis and org-mode tables are a natural match, so I have implemented integration between the two. As an example let’s create a 1000 random user login times (within the last 15 minutes) stored in the format above:
(let ((time-now (round (float-time))))
(dotimes (n 1000)
(let ((login-time (- time-now (random (* 15 60)))))
(eredis-set (format "user:%d" n) (number-to-string login-time) rp))))Now for debugging we want to see a table with login times of some users we’re interested in. That can be done like this:
(eredis-org-table-from-keys '("user:11" "user:21" "user:31" "user:41"))… which creates a table and inserts it in the buffer …
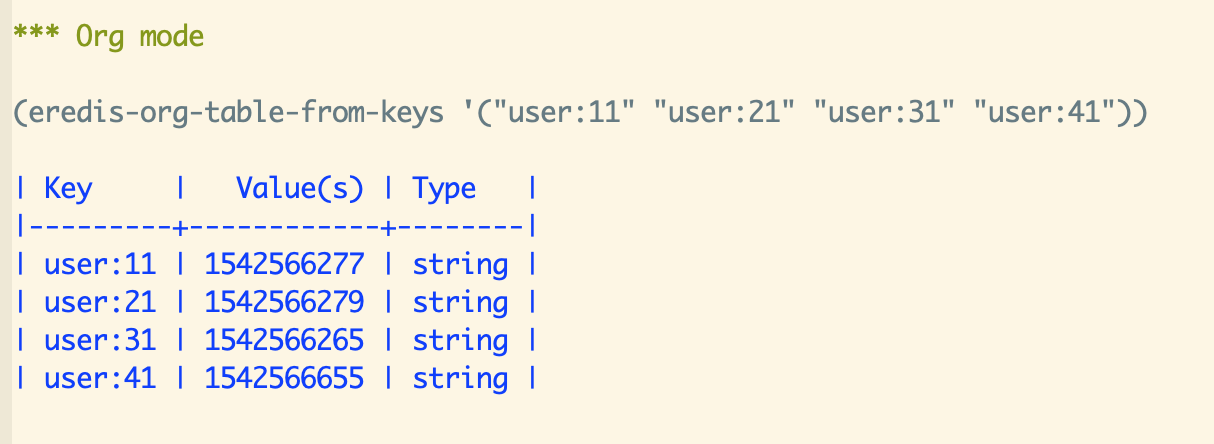
Of course it wouldn’t be any fun if the data flow was one way, so you can also edit the values (and keys) in the table and push them back up to Redis using the interactive command eredis-org-table-mset
If you create the table again in another part of the buffer you’ll see the values from your edit session have been stored to Redis.

Data processing
Another capability I recently added and that will be expanded on in future is the ability to iterate over all the keys in Redis using SCAN. Redis initially only had the KEYS * command for getting all the keys at once. Doing operations like that is a big problem when your data sets are very large. If you’re working with a real time data processing system you also don’t want to choke DB’s of any type by pulling huge amounts of data in single queries. For that reason Redis added the SCAN command so we can iterate through pages of keys and Redis can manage making sure that particular clients don’t overwhelm the system.
To this end I’ve added (so far) two facilities for iterating and reducing the entire key set, that wrap the SCAN command and let you focus on your data processing task. In addition at each step eredis pulls the values for each key using the MGET command. Now we can safely do map and reduce type operations over the keys and values in Redis!
Since I’m a fan of the dash.el list library, I use Dash commands to implement these functions, and then compile each page together transparently for the caller.
Earlier we added 1000 users. Let’s do a simple reduction to count them. There are two versions of this reduce function, one that also does a key name match eredis-reduce-from-matching-key-value and another that gets all of the keys eredis-reduce-from-key-value. Note the function names map to the dash.el reduce-from function and conceptually does the same thing but with transparent paging across the key space.
In this example we will simply count all of the users using the reduce.
(eredis-reduce-from-matching-key-value (lambda (acc k v)
(+ acc 1))
0
"user:*"
rp) ;; 1000
Here's a more useful example that actually uses the value (we stored a timestamp) in the reduction. We'll figure out how long each user has been logged in, total all the login times, and divide by 1000 to get the average time logged in:
(let ((time-now (round (float-time))))
(/
(eredis-reduce-from-matching-key-value (lambda (acc k v)
(+ acc (- time-now (string-to-number v))))
0
"user:*"
rp)
1000)) ;; 2450So the average login time is 2450 seconds, or about 40 minutes, which is because I created the test users around 40 minutes ago.
As well as reductions you can iterate over the users using each Note that this is not mapping over the key space as that would be very unfriendly to your Emacs environment if you have a lot of data. Map creates a new list of keys and values and holds them all in memory at once. All we want to do is iterate over the pages of keys and values, execute some function for its side effect, and continue on. There’s nothing stopping you materializing the entire key set in emacs should you need to, but it’s not supported by the eredis default API.
(let ((most-recent-login 0))
(eredis-each-matching-key-value (lambda (k v)
(let ((login-time (string-to-number v)))
(if (> login-time most-recent-login)
(setf most-recent-login login-time))))
"user:*" rp)
most-recent-login) ;; 1542566731Here we iterate all the keys and values and find the most recent login. Note that this could be done as a reduction too, there is some overlap between iterators and reductions.
What’s next?
Once eredis has stabilized and supports all Redis commands without bugs it will go to version 1.0.0
Before that however, the more immediate work is going into support for stream.el which allows us to construct lazy sequences. By implementing the SCAN functionality as a lazy stream we then can better compose operations on large data sets without blowing our memory. For example you can chain a couple of maps and filters together to transform your data before a final reduce to make it a single value.
In addition the org table support will be bolstered with bug fixes and new features.
I hope you enjoyed this quick tour of eredis and find a use for it, or at the very least see that emacs lisp programming can be fun, useful and quite simple.
This post is also published on Medium medium.com/@justinhj/eredis-an-updated-emacs-api