
Hacker News API Part 3
Previous related post: Hacker News API part 2
Github project related to this post
In part 2 of this series I presented an interative command line app that used the Fetch library to pull data from an online data source (the Hacker News API). In the related github repo I’ve developed that project in the following ways:
- Converted the code from a command line JVM app to a Scala.js app that runs in the browser
- Created a custom cache so we can query its size and clear it on demand
- Used Udash to create an interactive frontend to operate the fetches
- Visualize each round of the data fetch using reftree
You can check out the project live here
or watch a short video demonstration
What is hnfetchhs and how do you use it?
The idea of this blog post and accompanying github repo is to provide an interactive demo of the Fetch library. The Stories per page input field lets you specify how many stories to fetch from the API, whilst the Page input chooses the offset. In the background I use the top stories endpoint to get the IDs of all the top stories. The number of top stories known is shown in the title bar. At anytime you can reload the top story IDs using Refresh Top Stories.
Hitting the Fetch Page button will start a fetch job for the Ids with the current Page. So if you are are on page 1 and you have 30 stories per page you will get the top 30 stories as shown on Hacker News right now.
Once a fetch has been run you can view a diagram of the fetch operation in detail using the Last Fetch tab. If you play around with different page numbers and stories per page you can see the cache filling up, and you will see that repeated fetches of stories will result in a Nil fetch with no data to show.
You can also clear the current cache using the Clear Cache.
All these tools together make it easy to experiment with the fetch data source and different kinds of caches etc. The rest of the post explains some of the process involved in building this app.
What is Fetch?
Fetch, an open source project by 47 Degs, is inspired by the Haskell library Haxl developed at Facebook to simplify the concurrent retrieval of data from multiple sources. You can read more about that There is no Fork: an Abstraction for Efficient, Concurrent, and Concise Data Access
You can read more about Fetch at their documentation page https://47deg.github.io/fetch/docs.html
Converting code to scala.js
This is the first time I’ve ported code written for the JVM to Scala.js so it was a learning experience but also the shortest part of the project. I created a Udash frontend using the built in project generator and started moving my code into the new project a piece at a time. It involved doing the following:
Change library import paths
"com.47deg" %%% "fetch" % "0.6.3",
"com.lihaoyi" %%% "upickle" % "0.4.4",
"org.typelevel" %%% "cats" % "0.9.0"
This part was easy since these libraries are all available for scala.js. You just change the first @@ to @@@ and the scala.js library will be imported instead.
Java libraries
In my original code I used the PrettyTime library which is written in Java
"org.ocpsoft.prettytime" % "prettytime" % "3.2.7.Final"
and is not available to Scala.js since all code must be either compiled from Scala or Javascript. I found a similar library to PrettyTime called moment.js which had the functionality I needed. In order to use a Javascript library you must add it to the Assets folder and load it on your pages, and you need a facade type to wrap the Javascript API. Fortunately there is one already for the moment.js library, so by important that you can immediately start using it as if it were a Scala library.
"ru.pavkin" %%% "scala-js-momentjs" % "0.9.0"
Replace scalaj-http
Since fetching HTTP pages in my original code uses the ScalaJ HTTP library
"org.scalaj" %% "scalaj-http" % "2.3.0"
and this is not available in a scala.js version, I needed to replace it. Fortunately Javascript comes with the functionality needed to make requests to a a http endpoint. This is exposed to the Ajax library in scala.js. So removing the scalaj library and replacing the calls with Ajax was all that was needed.
You can see the implementation for this in the source file HNFetch.scala
def hnRequest[T](url: String)(implicit r: Reader[T]) : Future[Either[String, T]]
Custom DataCache
The DataCache interface in Fetch allows you to update the cache with new elements and to get a particular element from the cache if it is there. In order to write an interactive tool to explore Fetch I wanted to be able to show the number of elements in the cache. I also wanted to be able to empty the cache, but that’s straightforward, you just replace the existing cache with a new empty one.
Take a look at the code in Cache.scala for a simple DataCache implementation with the size function exposed.
Udash frontend
The Udash guide tells you everything you need to know to make great interactive frontends (and two kinds of backends) in a typesafe manner and entirely in Scala. I’ve used the Bootstrap add-on to utilize features such as tabbed panes to switch between the stories and the fetch diagram.
Visualizing the Fetch rounds
Probably the most interesting part of this project, although it was also fairly easy to implement, was the visualization of each fetch round.
For this I used reftree, and you can find out more about it in this video https://www.youtube.com/watch?v=6mWaqGHeg3g
Reftree takes care of the hard part of rendering the view using Javascript’s Vis.js (or GraphViz on the JVM), you just need to be able to translate your data into a RefTree by writing an implicit conversion:
implicit def fetchInfoToRefTree: ToRefTree[FetchInfo] = ToRefTree[FetchInfo] {
fetchInfo =>
RefTree.Ref(fetchInfo, Seq(
RefTree.Val(fetchInfo.count).toField.withName("count"),
fetchInfo.dsName.refTree.toField.withName("datasource")
))
}
implicit def roundToRefTree: ToRefTree[Round] = ToRefTree[Round] {
round =>
val fetchInfos : List[FetchInfo] = getRoundCountAndDSName(round)
RefTree.Ref(round, Seq(
RefTree.Val((round.end - round.start) / 1000000).toField.withName("ms"),
fetchInfos.refTree.toField.withName("Fetches")
))
}
Here’s a sample diagram of the Fetch rounds
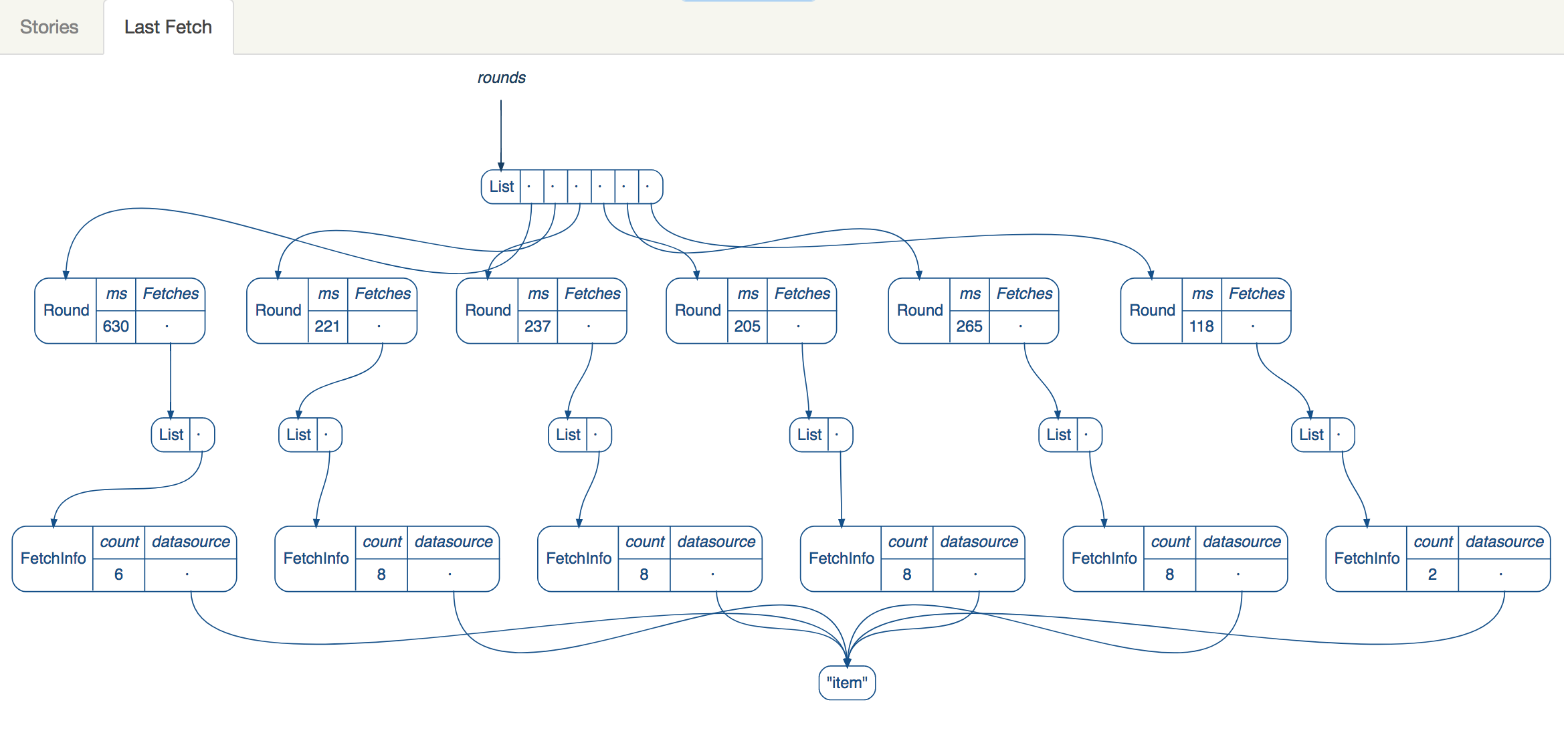
Here you can see that each round grabbed at least 8 items (that’s the number of items per round my data source specifies) and you can see the time in ms for each one. One thing to note is that the rounds are actually a queue not a list, but I found the list view was a lot easier to understand visually.
Next steps
Some ideas I have for extending the project:
- Do fetch and display of comments for the stories
- Interactive queries around users, stories and comments
- Periodic update of top stories animating the movers on the current page
Feel free to fork the code on github and expand it your needs, and as always feel free to contact me at the links above with any questions or comments.
Copyright (C) 2017 Justin-Heyes-Jones - All Rights Reserved